HPC Doctoral Taught Course Centre
JHD's slides from Tuesday 10 September.
JHD's Notes on C types from 12 September.
The C declaration explainer.
Case Study: Matrix Multiplication
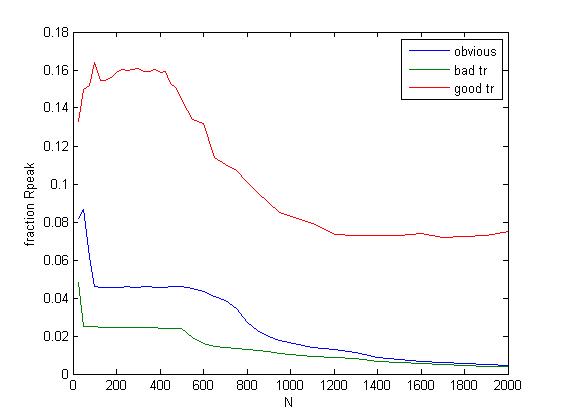
We consider what is probably the simplest HPC task, multiplying matrices, and we only consider (for simplicity) a sequential program running on one core of a dedicated node on Bath's HPC. This has 64KB of L1 cache and 6MB of L2 cache. e consider three fixed matrices A,B and C and compute C:=C+A*B.
There are three basic codes.
- Obvious(known as DGEMM in the code) c_ij:=c_ij+sum a_ikb_kj
- Bad Transpose(known as DGEMMtr in the code) c_ij:=c_ij+sum aT_kib_kj where aT is the transpose of a
- Good Transpose(known as DGEMMxtr in the code) c_ij:=c_ij+sum a_ikbT_jk where bT is the transpose of b.
We show here the performance, as a fraction of the potential peak performance, when the matrices are all sub-matrices of pre-allocated 2048x2048 matrices.
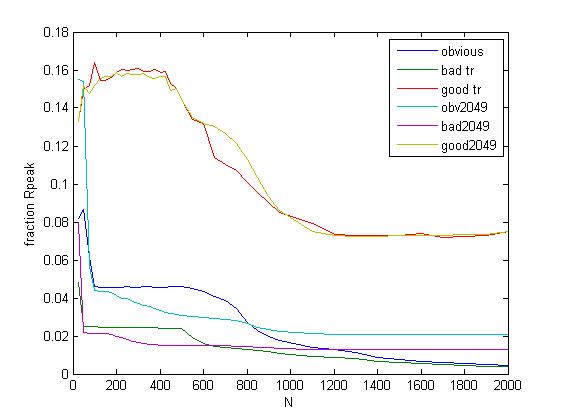
If instead we use chunks of a 2049\2049 matrix, we get different results, shown comparatively as this:
2048 and 2049 results
C programs
Factorial programs, C sheet 1.3.
Machine epsilon programs, NA sheet.
Argv example programs, C exercises.
{kind=link}
{kind=link}